
- 标题:Attention, Learn to Solve Routing Problems!
- DOI:10.48550/arXiv.1803.08475
Encoder
这玩意的encoder跟原教旨Transformer里的encdoer基本上是一模一样的,只是少了一个positional encoding,因为节点的位置不变,他觉得没必要传进去让它注意到。
The encoder that we use (Figure 1) is similar to the encoder used in the Transformer architecture, but we do not use positional encoding such that the resulting node embeddings are invariant to the input order.
包含两层,一层是多头自注意力机制MHA,然后就是一个前馈神经网络Feed Forward Neural Network(简称FFN)的传播。如下图(Figure 1)所示:
Each sublayer adds a skip-connection (He et al., 2016) and batch normalization (BN)
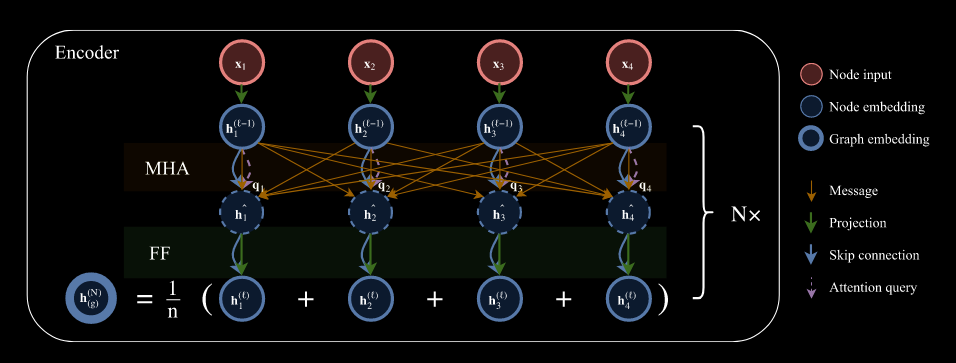
Encoder每一层都有一个残差连接skip-connection,最后拢共有一个批归一化/标准化batch normalization进行狠狠滴修正。
生成MHA所需要的embed_dim(h)
在这里我们要搞清楚MHA需要的embed_dim(h)是怎么来的,本质上Encoder通过一个线性映射将input (batch_size, graph_size, node_dim) 的node_dim便乘embed_dim。见论文:
From the dx-dimensional input features $x_i$ (for TSP $d_x$ = 2), the encoder computes initial $d_h$-dimensional node embeddings $h^{(0)}_i$ (we use $d_h$ = 128) through a learned linear projection with parameters $W_x$ and $b_x$: $h^{(0)}_i = W^xx_i + b^x$.
self.init_embedding = nn.Linear(node_dim, embed_dim)但是在实践中,我们要首先把节点特征的前两个维度合并一下子,从3d张量合并成2d张量,这样可以方便计算。形状就从(batch_size, graph_size, node_dim)->(batch_size x graph_size, node_dim)了
然后我们再使用self.init_embedding将node_dim线性映射为embed_dim,最后把前两个解出来,再把剩下的作为embed_dim。
改变形状通过.view()进行,只是改变索引样子,不会真正改变数据排列的形式,所以可以从3D->2D->3D
self.init_embedding(x.view(-1, x.size(-1))).view(*x.size()[:2], -1)MHA
可知方差公式为:
我们追求让方差等于一以让他波动程度最小,也就是$σ^2=1$移项可得$n\timesσ^2=1$,推导可得标准差$σ=1/\sqrt{n}$。
最后我们再让他均匀分布一下。
def init_parameter(self):
for name, param in self.named_modules():
# 输入向量x方差约等于1
stdv = 1. / math.sqrt(p.shape[-1])
p.data.uniform_(-stdv, stdv)判断query形状
由于我们使用自注意力,每次都要使用query来查别人的成分。所以query的形状是否跟h的形状符合就至关重要。
如果query查了h不存在的成分,那就是凭空捏造了。
batch_size, graph_size, input_dim = h.size()
assert batch_size == query.size(0)
num_query = query.size(1) #graph_size
assert input_dim == query.size(2)
assert input_dim == self.input_dim, "error message"张量大变动
首先我们将h和query的向量从3d降维到2d,也就是把三维的前两维合并,注释里面已标明形状变化。
# [batch_size * graph_size, input_dim]
h_flat = h.contiguous().view(-1, input_dim)
# [batch_size * n_query, input_dim]
q_flat = query.contiguous().view(-1, input_dim)形状已在注释里面标出,torch.matmul在做2Dx3D的时候会把2D的张量按照self.W_query第一个维度的样子加一个维度,从[batch_size * n_query, input_dim]变成[num_heads, batch_size * n_query, input_dim],然后再与3D张量做(实质上的2DX2D,在要求第一个参数的最后一个维度和第二个参数的第一个维度相同的前提下,把第一个参数最后一个维度和第二个参数的第一个维度去掉然后再把剩下的第一个和第二个维度合并)矩阵相乘,最后再按照定义好的张量样子改一下。
# 向量形状大定义, -1自动定义value_dim
shp_size = (self.num_heads, batch_size, graph_size, -1)
shp_query = (self.num_heads, batch_size, num_query, -1)
# q_flat:[batch_size * n_query, input_dim]-> [num_heads, batch_size * n_query, input_dim]
# self.W_query:(num_heads, input_dim, key_dim)
# [batch_size*n_query, num_heads*key_dim]
# ->[num_heads, batch_size, num_query, key/value_dim]
Query = torch.matmul(q_flat, self.W_query).view(shp_query)
# [batch_size*graph_size, n_heads*key/value_dim]
# ->[n_heads, batch_size, graph_size, key/value_dim]
Key = torch.matmul(h_flat, self.W_key).view(shp_size)
Value = torch.matmul(h_flat, self.W_value).view(shp_size)Compatibility大计算
由下列式子可得,我们需要一个query和一个key点积然后乘以norm_factory,由于Key的形状是[n_heads, batch_size, graph_size, key_dim]的样子,而2DX2D的乘法又要求第一个参数的最后一个维度和第二个参数的第一个维度相同,所以把key的后两个维度调换一下位置变成[n_heads, batch_size, key_dim, graph_size]
负无穷妙实现
注意到上面的公式里将不相邻的节点的Compatibility搞成-∞来实现屏蔽不相邻的节点,所以使用了掩码(mask)去实现这一点,expand_as(Compatibility)是把这套mask应用到所有节点,Compatibility[mask]会返回值是true的列表,这样我们就可以把这些都打成-∞:
# 用掩码去判断节点是否访问
# 给个1让所有mha都可以用
# [batch_size, num_query, graph_size]
if mask is not None:
# 1代表着只有一种mask,2需要搞两套mask约束条件然后分别扩展给相同多的头 8/2
mask = mask.view(1, batch_size, num_query, -1).expand_as(Compatibility)
# Compatibility[mask]是一种布尔掩码索引,这里是把所有返回的true都打成-inf
Compatibility[mask] = -np.infsoftmax算概率
我们将Compatibility的最后一维度(graph_size/num_query)拿来softmax算概率
possible = torch.softmax(Compatibility, dim=-1)调整输出的模样
# W_out: [num_heads, val_dim, embed_dim] -> [num_heads x val_dim, embed_dim]
# [batch_size x num_query, num_heads x value_dim] x [num_heads x val_dim, embed_dim]
# -> [batch_size x num_query, embed_dim] -> [batch_size, num_query, embed_dim]
out = torch.mm(
heads.permute(1, 2, 0, 3).contiguous().view(-1, self.num_heads * self.value_dim),
self.W_out.view(-1, self.embed_dim)
).view(batch_size, num_query, self.value_dim)特别注意
softmax的输入要有一个1/\sqrt{n}的缩放因子,因为方差总共期望是1,经过一些叽里咕噜的数学推导可以出来这个缩放因子。attention is all you need里面有证明,参数初始化部分的简易推导仅供理解。
self.norm_factor = 1 / math.sqrt(key_dim)Feed Forward Neural Network
The feed-forward sublayer computes node-wise projections using a hidden (sub)sublayer with dimension dff = 512 and a ReLu activation:
FFN部分就很朴实,是用一个512维度隐藏的子层(hidden (sub)sublayer, feed_forward_hidden)和一个ReLu激活函数组成的。进行升维然后降维确保输出一致。
将embed_dim啪唧线性映射成feed_forward_hidden然后走一层ReLu挨个点名激活后再线性映射回来。
nn.Sequential(
nn.Linear(embed_dim, feed_forward_hidden),
nn.ReLU(),
nn.Linear(feed_forward_hidden, embed_dim),
)残差连接
残差连接就一个 x + f(x),把x(输入)加上模型的输出里面,这样可以避免梯度锐减,具体的数学推导待写。
class SkipConnection(nn.Module):
def __init__(self, x):
super(SkipConnection, self).__init__()
self.modules = x
def forward(self, x):
return x + self.modules(x)批标准化
We use batch normalization with learnable $d_h$-dimensional affine parameters $w^{bn}$ and $b^{bn}$:
这里我们直接用现成的批标准化就行,传入标准化的每个参数也要进行一个相同的初始化标准差,见参数初始化。
self.normalizer = nn.BatchNorm1d(embed_dim, affine=True)在前向传播里面我们只需要在批标准化的分支里面进行批标准化就可以:
if isinstance(self.normalizer, nn.BatchNorm1d):
# [batch_size, num_xxxx, embed_dim] -%3E [batch_size x num_xxxx, embed_dim] -%3E [batch_size, num_xxxx, embed_dim]
# *input.size() 获取原始输入的样子
return self.normalizer(input.view(-1, input.size(-1))).view(*input.size())准备输出
其实这节之所以会写是因为n久以后再看把自己绕进了,倒腾半天才搞明白自己的那堆注释
num_heads, num_layers, embed_dim,
在Encoder这里,我们的输入是(batch_size, graph_size, node_dim)。为了将这些原始节点特征进行处理,我们使用一个线性变换将node_dim便乘embed_dim来进行初始化嵌入向量。于是我们便得到了embed_dim这个东西。
Encoder里面的样子其实是这个样子:
SkipConnection(MultiHeadAttention(num_heads, input_dim=embed_dim, embed_dim=embed_dim)),
Normalization(embed_dim, normalization),
SkipConnection(
nn.Sequential(
nn.Linear(embed_dim, feed_forward_hidden),
nn.ReLU(),
nn.Linear(feed_forward_hidden, embed_dim),
)
),Normalization(embed_dim, normalization)也就是将embed_dim与确定好的MHA头的数量(num_heads)经过残差链接(SkipConnection)后塞入MHA让他算各个节点的权重,算完后标准化一下数据再进入FFN里面,也就是就是这个抽搐样子:
经过残差链接(SkipConnection)丢进FFN层后用ReLU激活函数激活一下后再丢进FFN层进行前向传播。
nn.Linear(embed_dim, feed_forward_hidden),
nn.ReLU(),
nn.Linear(feed_forward_hidden, embed_dim),We use N = 3 layers in the encoder, which we found is a good trade-off between quality of the results and computational complexity.
Encoder层一共跑三次,也就是Encoder里面的MHA+FFN,然后我们得到了Encoder的输出:
- node_embedding(h)
- graph_embedding(h.mean(dim=1))
Decoder
The decoder computes an attention (sub)layer on top of the encoder, but with messages only to the context node for efficiency.
送走了Transformer Encoder,我们喜迎Attention Decoder。我们使用Encoder算出Embedding里面的权重后再使用Decoder算出一个囊括所有节点的概率分部,选择下一个节点,然后再来一遍。
将输出再初始化嵌入
书接上回encoder给出的h,那时候我们把(batchsize, graph_size, node_dim)里面的node_dim通过线性变换便乘了embed_dim。
现在我们将这个操作重来一遍,之所以我们选择使用`embeddings, `这种写法是因为encoder的第二个输出会给一个graph_embedding,而这个东西在decoder里面用不上,所以给丢掉了。
embeddings, _ = self.embedder(self._init_embed(input))将其他类型问题的额外参数加入
self.init_embed(torch.cat((
input,
*(input[feat][:, :, None] for feat in features)
), -1))原本的node_dim是(x,y)张量,现在遍历每个feature并且通过torch.cat拼接加入进node_dim里面
额外小花招之checkout节省显存
论文里面使用了一个叫gradient checkpointing的节省显存的技术,其存在于torch.utils.checkpoint。其作用是老蒋的空间换时间的反向:用时间换空间。
当没使用这个技术的时候,在每次前向传播的时候encoder中间层都会保存一个激活值,而我们要跑3次前向传播,其显存占用是3倍的。于是则有了这个技术,当最终到了反向传播backward的时候会把每次forward重新跑完再算梯度进行修正参数。由于checkjpoint只接受tensor参数,所以我们把这个嵌套拆出来写。
if self.checkpoint_encoder and self.training: # Only checkpoint if we need gradients
embeddings, _ = checkpoint(self.embedder, self._init_embed(input))
else:
embeddings, _ = self.embedder(self._init_embed(input))precompute预处理静态信息
要把几个固定的东西提前计算好,这样预制好了可以直接把这几个静态不会变化的东西端过来配合动态变化的stage信息给后面计算节点概率使用:
- graph_context (整张图的全局表示)
- glimpse_key
- glimpse_value (前两个用于 decoder 的 glimpse attention)
- logit_key 用于最终计算每个节点的 logits
graph_context
首先将图嵌入graph_embed用graph_size求一下图里所有节点嵌入求平均,然后线性变换一下中间插个1维度None张量以表示这是不变的全图嵌入。
这里应该直接引用encoder的第二个返回就好了,而非直接使用encoder的第一个返回再求平均
# (batch_size, graph_size, node_dim) → (batch_size, node_dim) → (batch_size, node_dim)→ (batch_size,1, node_dim)
graph_embed = embeddings.mean(1)
fixed_context = self.project_fixed_context(graph_embed)[:, None, :]glimpse_key glimpse_value logit_key
这里的节点嵌入来自于encoder的第一个返回
因为decoder第一次glimpse attention(mha)时会以fixed.context_node_projected + step_context_projected的方式构造query,其中 step_context_projected 的形状是(batch_size,num_steps, node_dim) ,所以给中间掺和进去一个维度便于待会broadcast的时候可以直接把这个None改写成对应的每个step上。
注意这里的.chunk(3, dim=-1)会把最后的node_dim搞出三套分别给这哥仨使得他们分别都可以是(batch_size,1, graph_size, node_dim) 。
#(batch_size, graph_size, node_dim)→ (batch_size,1, graph_size, 3xnode_dim)
#project_fixed_context其实就是linear一下罢了
self.project_fixed_context = nn.Linear(embedding_dim, embedding_dim, bias=False)
glimpse_key_fixed, glimpse_val_fixed, logit_key_fixed = \
self.project_fixed_context(embeddings[:, None, :, :]).chunk(3, dim=-1)glimpse_key是decoder第一次glimpse attention(mha)时使用的key,glimpse_value是decoder第一次glimpse attention(mha)时使用的value,而logit_key则是decoder最后计算每个节点的最终概率的时候所需要的两个东西之一,第一次glimpse attention后得到的glimpse和logit_key送进最后的mha计算输出概率。
最终输出
我们把这些东西这些固定量打包成AttentionModelFixed供后续计算概率反复使用:
- 原模原样的输出给进来的嵌入
- 计算好的
graph_context(也就是这里面的fixed_context) - 第二个小标题讲到的三巨头(为第一次glimpse attention准备的query的静态量)。
# No need to rearrange key for logit as there is a single head
fixed_attention_node_data = (
self._make_heads(glimpse_key_fixed, num_steps),
self._make_heads(glimpse_val_fixed, num_steps),
logit_key_fixed.contiguous()
)
return AttentionModelFixed(embeddings, fixed_context, *fixed_attention_node_data)state动态上下文
把当前的state压成一个适合decoder在glimpse attention(mha)时使用的context。
他根据每种问题的不同而把step context分成不同的形状:
例如在tsp中则是一个从第一个节点和现在节点的嵌入(还捏着第一个节点是为了知道出发点在哪里):[first_node_embedding ; current_node_embedding],也就是(batch_size,1, 2xnode_dim)
当然第一步的选择里肯定没有这两个节点,所以我们塞进去一个W_placeholder这种起始状态向量作为第一步的step context,这样可以复用上面的选择。
if num_steps == 1: # We need to special case if we have only 1 step, may be the first or not
# First and only step, ignore prev_a (this is a placeholder)
return self.W_placeholder[None, None, :].expand(batch_size, 1, self.W_placeholder.size(-1))而在VRP、OP、PCTSP等问题里面则由于他们加入了一些feature,所以就会简化变成当前节点的embedding与一个动态标量,如下面这样子:
- VRP:
[current_node_embedding ; remaining_capacity] - OP:
[current_node_embedding ; remaining_length] - PCTSP:
[current_node_embedding ; remaining_prize]
映射调整输出
我们把这种类似于(batch_size,1, 2xnode_dim) 的形状通过线性变换把它投影回(batch_size,1, node_dim) 以便喂给query进行计算使用。
inner主循环循环
我们通过这个又臭又长的主循环一步一步地去把每个节点的路径跑完
首先先摆俩空张量预备着村输出和选好的节点序列,然后把state内部存在的掩码、当前节点、第一个节点、步数摆出来列出满满一排。
state = self.problem.make_state(input)计算节点概率
组装glimpse attention(mha)时使用的query:
query把两组信息相加,一个是静态的precompute好的固定上下文,一个是动态的state的上下文。
query = fixed.context_node_projected + \
self.project_step_context(self._get_parallel_step_context(fixed.node_embeddings, state))同时我们拿到glimpse attention(mha)所需要的,上文已经计算好的glimpse_key glimpse_value logit_key。
glimpse_K, glimpse_V, logit_K = self._get_attention_node_data(fixed, state)然后我们再从问题描述里面拿到mask掩码:
# (batch_size,1, node_dim)
mask = state.get_mask()glimpse attention(mha)算候选节点得分:
这里跟上面的mha其实原理是一模一样的,我们拥有query(batch_size,1, node_dim) ,然后将query拆分开,变成(num_heads, batch_size, num_steps, 1, key_size) 这里的key_size还是node_dim 除以num_heads得来的,依旧按照compatibility的公式bangji一套算得分。
后面就是熟悉的给mask打-inf,softmax得到attention权重,attention权重去跟glimpse_value这么个$\sum_ja_jv_j$加权相加得出glimpse(中间有一步把num_heads与key_size相乘拼接出node_dim)。
然后我们把拿到的glimpse与那个logit_key相乘后除以glimpse的node_embeding的根号,也就是这个形状:(batch_size,1, node_dim)
我们可以得到 还没有归一化的logit(节点概率) 。
logit = torch.log_softmax(log_p / self.temp, dim=-1)通过对他进行一个softmax,除以一个叫temperature(温度的东西)进行归一化概率。通过对他进行一个softmax,除以一个叫temperature(温度的东西)进行归一化概率。
- temperature小:分布更尖锐,更偏向最大值
- temperature大:分布更平缓
于是现在得到了log probabilities(节点概率) 与 glimpse 。
选择下一个节点
有两种选择方式:
- Greedy:选择概率最大的节点。
- Sampling:按概率分布随机采样一个节点。
同时保证选中的节点没被访问过(如果mask存在的话) probs.max(1)则是选择了那个最大概率的节点,probs.max(1)[1]则是选择了那个节点中的(batch_size),当然不是[0]是因为这个是他的概率multinomial(1)从probs中根据概率分布随机选择一个节点,.squeeze(1)是为了去掉额外的维度,使得selected变成(batch_size)形状(直接得到那个节点对应的索引)selected.unsqueeze(-1)则让他变成(batch_size,1)的形状进而与mask对齐
def _select_node(self, probs, mask=None):
# 这里其实还是要检查一下是否有mask存在的,论文里给的是注释过的那一个assert
#assert (probs == probs).all(), "Probs should not contain any nans"
if self.decode_type == "greedy":
selected = probs.max(1)[1]
elif self.decode_type == "sampling":
selected = probs.multinomial(1).squeeze(1)
if mask is not None:
while mask.gather(1, selected.unsqueeze(-1)).data.any():
selected = probs.multinomial(1).squeeze(1)
return selected最后我们使用诸如state.update更新节点状态就完事了。
forward反向传播
计算log likelihood
这个东西是REINFORCE 的损失函数。我们的目标是最大化 log likelihood,也就是生成路径的概率。
计算给定路径的log likelihood(对数概率),也就是把log_p里面有效节点的概率取出来去求和计算最终路径的log likelihood。
- log_p是上面的softmax后的log probabilities,形状是
(batch size, num_steps, node_dim) - a是每个batch中生成的索引,a.unsqueeze(-1)也就是
(batch size, num_steps, 1) - .gather(2, a.unsqueeze(-1))提取出对应路径的中每个节点log probabilities
- .squeeze(-1)是把最后一个维度去掉变成
(batch size, num_steps) - 最后再将没有映射到的取零,也就是_log_p * mask.float()
_log_p = log_p.gather(2, a.unsqueeze(-1)).squeeze(-1)
_log_p = _log_p * mask.float()
return _log_p.sum(1)REINFORCE与Greedy Rollout baseline
reinforce_loss = ((cost - baseline) * log_likelihood).mean()这个等价于这个梯度更新公式:
将cost与baseline相减得出来的Δ(判断好坏)与likelihood相乘取平均来得到梯度。
cost则来源于问题定义的回报,也就是:
cost, mask = self.problem.get_costs(input, pi)模型参数更新
我们使用adam优化器 把前面算好的梯度丢给adam优化器来更新参数,实现模型的更新。在推理阶段的时候我们只使用init_embed后就把输入丢给decoder然后产出路径就完事了。
Comments NOTHING